A few months ago, while “window” shopping at Ebay, I came across something that I thought to be an unbelievable deal. I found a Fusion-IO ioDrive Duo 640GB MLC PCI-E SSD for the crazy low price of.. well on second thought, maybe disclosing the price isn’t such a good idea. I never know when my wife may visit this site lol. Anyway, suffice it to say, the price was very good so I bought it. As to the reasons behind well you’ve already read the title so I think you know where this is headed haha.
The Prologue
So like any good techie worth his salt, I subscribe to a number of forums, mailing lists and the like. The lists I watch add up to hundreds, if not thousands of messages per month, so there is no way I get to read them all. I generally skim through the subject lines for interesting topics like serious bugs or major releases. Well last year, I saw several interesting threads come across related to DRBD that really REALLY got my attention. One is archived here and the other here. The reason they got my attention is because a while back, I had a project to research and implement some form of HA for an open storage platform. For that project, I decided to use DRBD in conjunction Mellanox 10GB Infiniband HCAs to replicate data from the primary system to a passive/backup system. I choose Infiniband because the price-per-port for 10gb Ethernet was still very high, the amount of good, used IB hardware on EBAY was plentiful and because DRBD seemed to have support for the Sockets Direct Protocol (SDP).
SDP (now depreciated) uses RDMA which means high speed, zero copy data transfers. Having hardware that facilitates high speed data transfers critical because blocks have to be committed on the DRBD partner before they are committed locally. This could mean a bottleneck if your disk subsystem is able to sync data much faster than replication link can transfer it. Unfortunately, my testing didn’t yield the expected results. I could not get SDP to work so I had to fallback onto IBoIP which only provided 1/3 of the throughput the system was capable of. Needless to say I was disappointed. That is specifically why when I came across the above threads, I became really excited and set off on a new adventure. After a few months of getting together a sufficient test environment, research and testing, what I managed to cobble together looks somewhat like this:
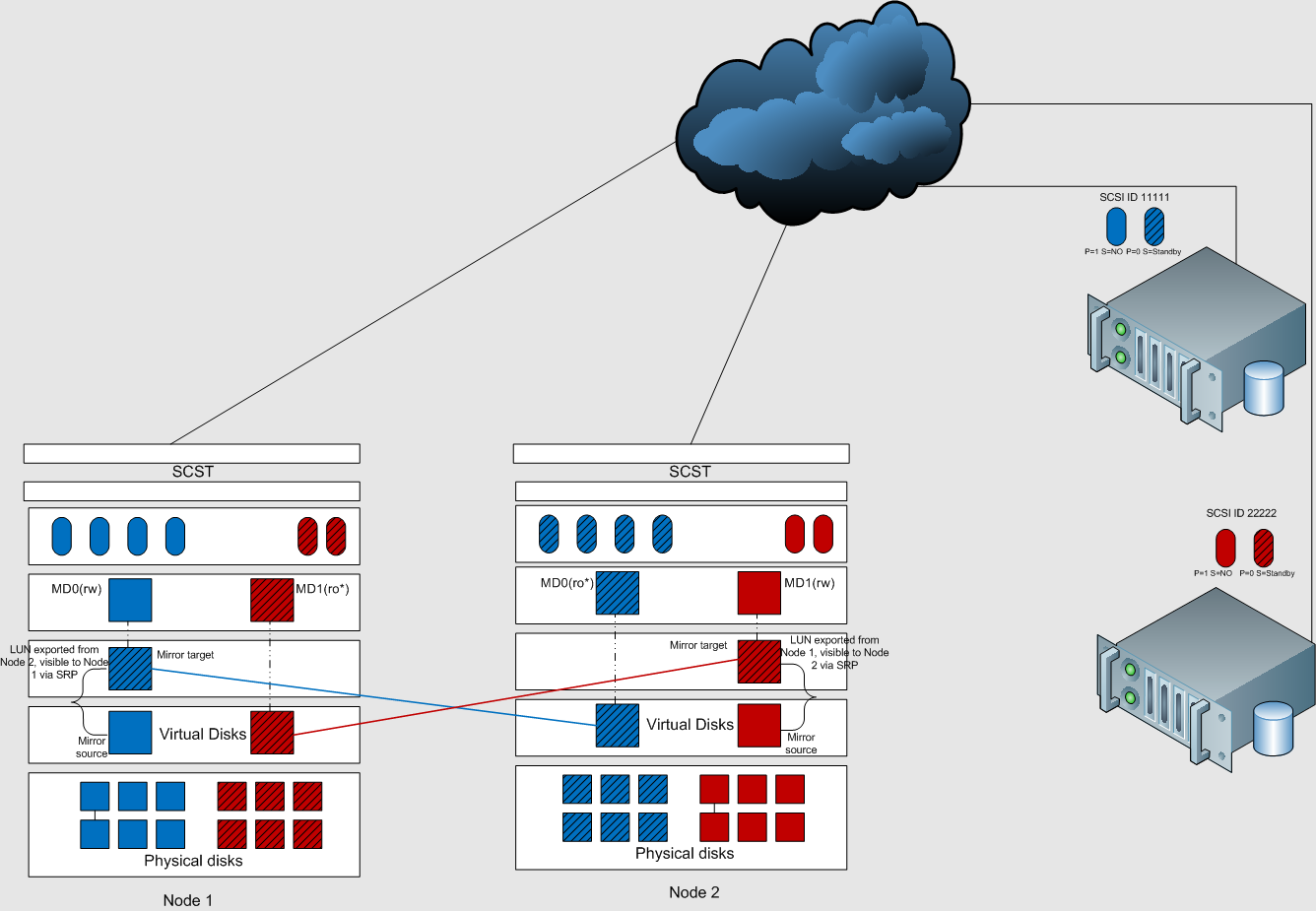
What my poor illustration is trying to, well, illustrate is a two node, active/active storage system whereby using the built-in software RAID 1 capabilities of Linux, data is mirrored to a remote LUN that each node exposes to the other over SRP. The easiest way to understand the the image is to imagine two services; one blue and one red. Node 1 is the authoritative owner of the blue service and Node 2 is the authoritative owner of the red service. Each node mirrors its authoritative service to its counterpart so in other words, each node is both a target an an initiator.
Take for instance the blue service. Its running authoritatively on Node 1 and passively on Node 2. Since each node effectively has the same data, the service can be exposed from both nodes over fabrics like iSCSI and Fibre Channel so long as an implicit ALUA configuration is honored by the initiator that says the blue service running on Node 2 is a “standby” path and should only be used when all other paths have failed.
The illustration is a little old as it doesn’t quite reflect my 2.0 version of “service” delivery. In the diagram above, you see a single MD device and each service is carved from. In my improved version, I decided to use a one-md-per-lun model for each service which I feel will scale better and offer HA only for services that want/require it. I just haven’t gotten around to recreating the diagram
Now for the most part, this is was “working” working well. For older gen IB hardware, the performance far exceeded my expectations and I even considered purchasing some more current hardware to do further testing. I had planned on writing up my tests and blogging about it, but I had roughly three concerns that made me change semi-scrap the idea.
- Complexity
- Scalability
- LSI Syncro
In a nutshell, this configuration is really complex. It has a lot of moving parts and some of challenges that I’m still working through are fault detection, failover, failback…essentially all the parts that would screw up your data if they didn’t work properly lol. To that end, I started to write a resource agent for Pacemaker to handle some of this modeled after the MD RAID1 RA and the ESOS HA agent, but its far from complete.
Also, an HA solution of this nature may be costly to scale out since each node will require its own storage pool. This means having to purchase 2x the storage which I’m sure wouldn’t look good in the marketing materials.
Lastly, the LSI Syncro CS Controller. This is probably the main reason that i felt like scraping the idea/project. The LSI Syncro product I feel is a game changer when it comes to Open Storage platforms. If you aren’t familiar with it, you should check it out. Essentially it allows two LSI RAID controllers to connect to and share the same DAS storage. Although LSI was not the first to make such a controller (IBM made one several years ago), they are the latest and as such, their controller is a now() gen controller with SAS 6G support, 1G cache and current OS support. From the perspective of what I need in an HA solution, the LSI Syncro product certainly seems to answer the mail, though at the expense of a moderately priced, proprietary hardware solution. That said, if you aren’t relying on something like ZFS or Storage Spaces (Windows Server 2012) you are going to be using someone’s proprietary RAID controller right? In addition, as I said earlier, scalability could be an issue with my configuration. With Syncro, storage is shared between nodes so you don’t need to purchase twice.
So in conclusion, as much as I think my setup has some potential and could be useful for small shops with existing hardware for a quick “poor mans” HA solution, but I think for new deployments, LSI Syncro may be the way to go.
Wow, check out the post of one my IT hero’s, the creator of ESOS, Marc A Smith, here about using with LSI Syncro with SCST. Thanks Marc!
Promises, Promises…
Now you are all probably wondering what the heck does all that have to do with me buying an ioDrive. Well its simple. An affordable HA solution for an Open Storage based SAN is one of my “Holy Grail”s. Its something I’ve pursued over the years and have not really found. You see the reason I purchased the ioDrive was because of my pursuit of another Holy Grail. Another relic that has been calling out to me ever since I got wind of its existence. That relic my friend is the promise of Hybrid Storage Pools.
The term Hybrid Storage Pool is something I became aware of roughly between 08 and 09 when I began experimenting with COMSTAR on OpenSolaris and Solaris Express. The ability of ZFS front slower 7200 RPM HDDs with flash or SSDs as an accelerator or cache sounded promising. SSD and Flash based storage at the time was still very expensive per GB and as much as deploying a chassis full of expensive, performant SSDs would make every stuff “scream”, who can really afford that? However, the promise of the Hybrid Storage Pool seemed to be that you didn’t need a chassis full of SSDs or Flash to get a pool wide benefit. What I imagined was that I could I could use a 80/20 ratio of HDD to SSD which would be tantamount deploying 40 – 60% more HDD spindles. I was sold! I think we invested somewhere between 5 and 7K but the project was filled with hardware issues and other implementation challenges like server boards failing, ZFS/Solaris bugs.
The final nail in the coffin was when Oracle purchased Sun which ultimately spelled doom for OpenSolaris and COMSTAR. So, when I saw the ioDrive Duo for what I knew was a ridiculously low price up for sale on Ebay, and my test environment was already warmed up, I could not resist purchasing it. I felt like the other Holy Grail that I had been searching for over 5 years ago was calling out to me with the same promise. I just had to find out if the promise was true!
So now that you have the ENTIRE background and history of how we arrived here. Lets talk brass tacks shall we? Is this promise real? Can you get near SSD performance out of spinning platter with the right hardware, software and configuration? Time to dig into the geeky details!
Enter The Candidates
Based on some past research before even attempting this project, I knew there several promising projects that were test candidates. Those projects are:
- FlashCache
- Bcache
- Dm-Cache
- ZFS On Linux
- EnhanceIO
To make sure I wasn’t overwhelmed with this project and can actually deliver a result, I decided to test ZFS, Bcache and made several attempts to test EnhanceIO, but the current code appears to have a show stopping bug that crashed my system during any kind of load. I opened an issue/bug report at STEC’s git code repo that included a full stack trace, but it doesn’t seem like I’m the first person to encounter this problem. In reading some of the open issues, it seems that HGST (Western Digital) purchased STEC so the future of EnhanceIO may be in jeopardy. Only time will tell.
Test Methodology and Parameters
Benchmarking storage performance sometimes can be a real challenge. There are lots of free tools that would normally use like IOmeter or fio but for this test, I decided to to take a different route. I wanted to see how the storage performed through the lens of a complex application that could benefit immensely from read and write caching so I decided to stand up an Oracle Database instance and use the SLOB toolkit to do my dirty work.
SLOB stands for the “Silly Little Oracle Benchmark”. The author of this invaluable tool is Kevin Clossan (see his blog here). I won’t spend too much time talking about SLOB as its very well documented, but SLOB is an excellent tool for generating Oracle specific workload. Please visit the author’s blog for more information.
I’m also using a harness/wrapper created by another SLOB user (flashdba) called slob2-harness which is available here The harness will provide some test automation as the SLOB toolkit has a number of dials and knobs to adjust. My static parameters in slob.conf are:
| SLOB Static Parmeters | |
|---|---|
| RUN_TIME | 300 |
| SCALE | 100000 |
With the aid of the harness, I’m going to run 21 tests, each with a different WORKER and UPDATE_PCT configuration.
| SLOB2 HARNESS Parmeters | |
|---|---|
| UPDATE_PCT | 0,10,20,30,40,50,60 |
| WORKERS | 0,64,128 |
By adjusting the UPDATE_PCT parameter in increments of 10 from 0 to 60, we are essentially going from a 100 percent read workload to mixed workload. The idea here is to essentially find what would be the sweet spot in terms of workload and mix of reads and writes.
Hardware and Testbed Configuration
So for this test, I have two physical servers, one for my storage platform and the other to run ESX.
| Open Storage Server Test Platform | |
|---|---|
| Server Model | Power Edge R515 |
| CPU | 1x AMD Opteron(tm) Processor 4130 |
| Memory | 32 GB |
| RAID Controller | Dell H700 |
| Infiniband HCA | ConnectX VPI PCIe 2.0 2.5GT/s – IB DDR / 10GigE |
| OS | Ubuntu Server 14.04, kernel 13.13.0-32-generic |
| Boot Drive | 2x Seagate Savvio 10K.3 146 GB RAID1 |
| Backing Store | 12x HGST Ultrastar 15K 600 GB RAID5 |
| SCST Version | 3.1.0-pre1 Trunk 5682 |
| ZFS Version | 0.6.3-2 |
| Bcache Version | In kernel tree |
| Fusion-IO FW/Driver Version | v7.1.17, rev 116786 Public/3.2.8.1350 |
| VMWare ESX Server | |
|---|---|
| Server Model | Power Edge R515 |
| CPU | 2x AMD Opteron(tm) Processor 4184 |
| Memory | 132 GB |
| RAID Controller | Dell H700 |
| Infiniband HCA | ConnectX VPI PCIe 2.0 2.5GT/s – IB DDR / 10GigE |
| OS | VMware ESXi,5.5.0,1623387 |
| Primary Datastore | 12x HGST Ultrastar 15K 600 GB RAID5 |
If you haven’t guessed it already, since I’ll be running the Oracle DB on a VM. I decided to go this route for two reasons:
- Easier for me in case I want to spin up a Windows VM running SQL Server to run similar tests
- Virtual DB servers are more common these days organizations take on a “virtualize everything” policy on server deployments
Details are below.
| Test Oracle 11g DB Platform | |
|---|---|
| CPU | 1 VCPU |
| Memory | 8 GB |
| OS | Oracle Linux Server, kernel 2.6.32-431.el.6.x86_64 |
| Boot Drive | 100GB |
| Database Version | 11.2.0.3.0 |
The database was created using the standard Oracle template for General OLTP databases. The only changes I made were to increase the log group size to 1GB and add two more groups for a total of five. As far as data storage for the instance, for each test case, I did the following steps:
- Create the device on Storage Platform
- Export the device to the ESX initiator as lun 0
- Rescan the HBAs on the ESX initiator
- Ensure Round Robin MPIO
- Attach the disk as a RDM to the VM (-z flag for vmkfstools)
- Scan the SCSI HBA on the VM (appears as sdb)
- Partition sdb starting at 2048s to -1s with parted
- Create an ASM disk, “DISK1” from sdb1
- Create an ASM diskgroup “+DATA” from DISK1
- Create the Oracle instance using “+DATA”
As step 1 mentions, I needed to create a device on the storage platform to export to the initiator. Here are the parameters that went into each solution configuration:
| Device Parameters | |||
|---|---|---|---|
| Solution | SSD Storage (GB) | HDD Storage (GB) | CMD line |
| ZFS | 50 | 500 | zpool create -f data sdb1 cache md0 |
| EnhanceIO | 50 | 500 | eio_cli -d /dev/sdb1 -s /dev/md0 -p lru -m wb -c eio_cache |
| Bcache | 50 | 500 | make-bcache-B /dev/sdb1; make-bcache -C /dev/md0; echo writeback > /sys/block/bcache0/bcache/cache_mode; echo f3e8bd9c-60e6-4cd5-9a46-b32fac8ea01c > /sys/block/bcache0/bcache/attach |
| HDD | NA | 500 | NA |
| SDD | 300 | NA | NA |
You’ll notice that i’m using an MD device for the SSD. This is because the Fusion-IO Duo (as it name implies) is actually two 320 GB SSDs. You can run them as RAID0, but I need to ensure the utmost integrity, so I chose to use RAID1. For the 50GB tests, I simply created a 50GB slice of each SSD, /dev/fioa and /dev/fiob and created an MD device from that. For the standalone tests, I created an MD device using all the available space for both SSDs
To put things into perspective, I also needed to perform tests of the Fusion-IO SSD and the H700 RAID device stand-alone.
Results
One other thing that is great about the SLOB toolkit is that it spits out AWR reports for each run in html and text format. An AWR report is an invaluable tool when it comes to getting to the bottom of your database’s performance. There is a-lot of information contained in a report, and its easy to become overwhelmed and lost in the data if you aren’t an expert already.
I found a great presentation on interpreting the report which can be found here. Fortunately for us, flashdba wrote a nice little shell script called slob2-analyze that you can run against the SLOB produced AWR reports to extract the I/O specific report elements into nice little CSVs which can then be plotted using Excel or other such tools. Thanks flashdba for makring this easier for me!
So first up, lets look at a basic read workload with 1 worker and update_percent = 0.
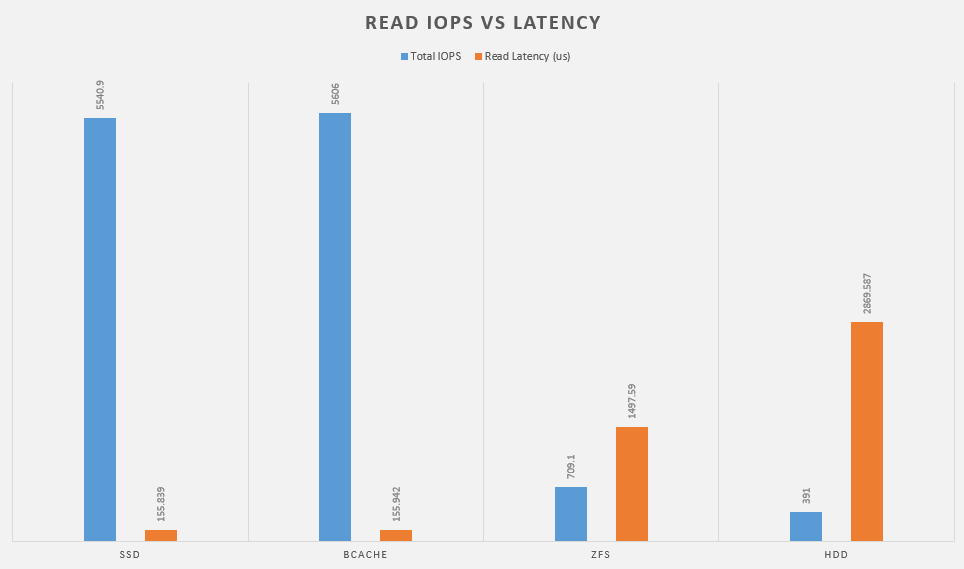
This gives me a baseline of read performance. Whats interesting here is that bcache solution actually performs a little bit better than the plain SSD. The clear winner here is bcache with zfs nearly doubling the RAID array’s performance.
Next up is the same test, but I want to see how each configuration perform when you scale up the workers.
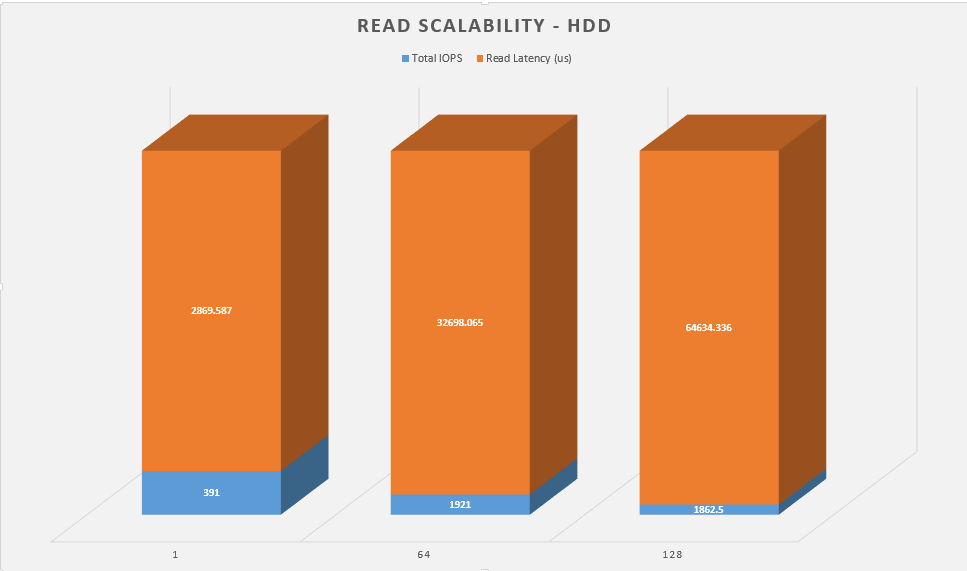
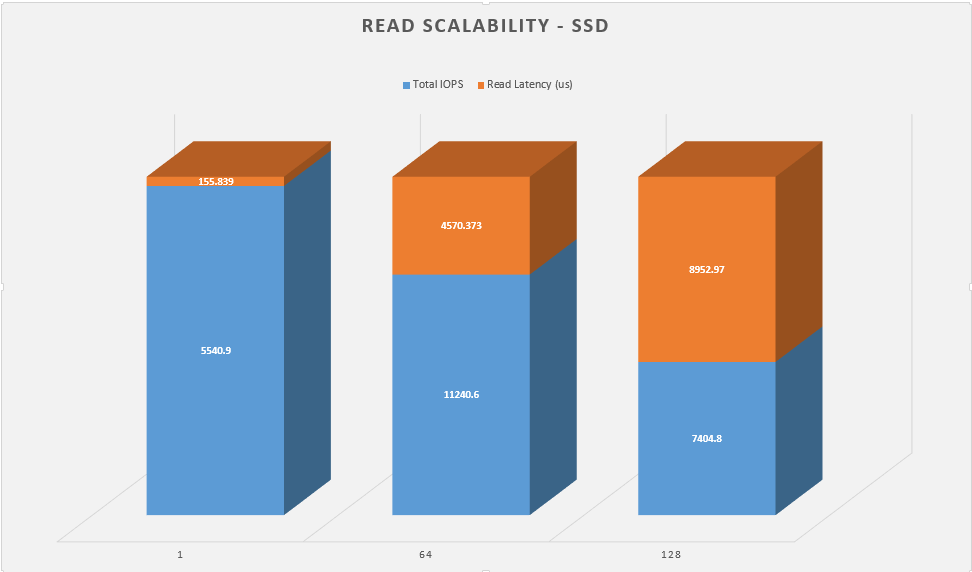
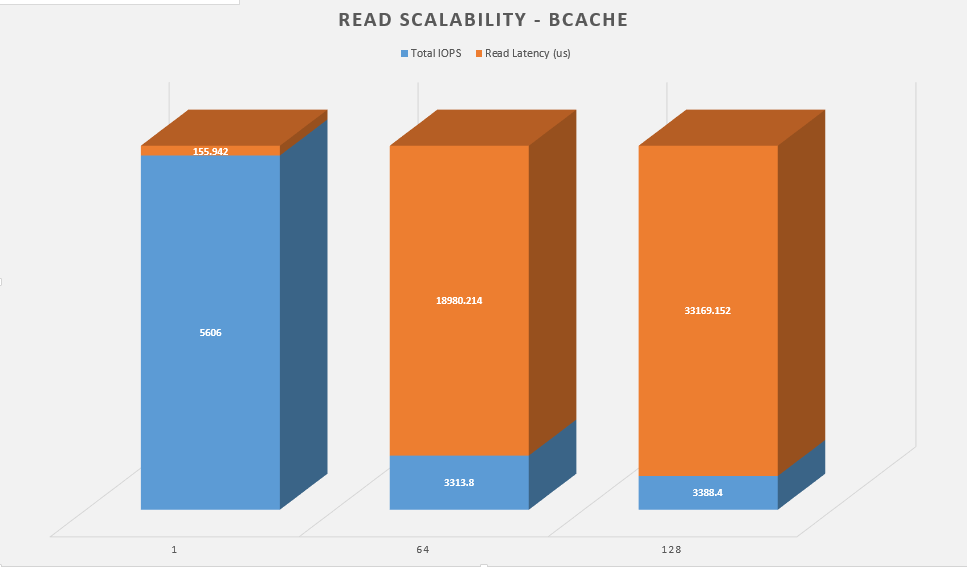
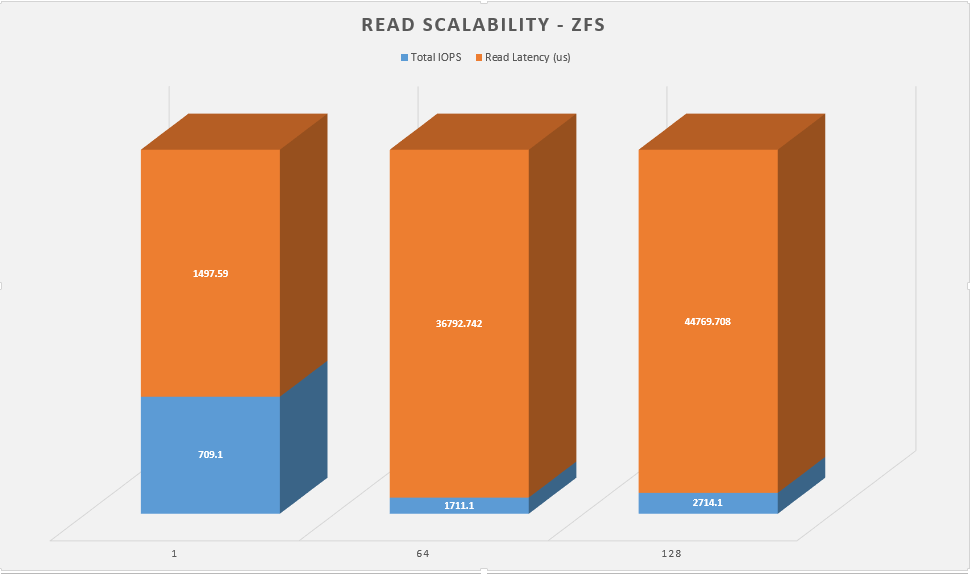
Again, the clear winner here is bcache nearly doubling the performance of the RAID array, but even still, zfs is no slacker.
Next, lets look at how the devices perform when we mix in a write workload.
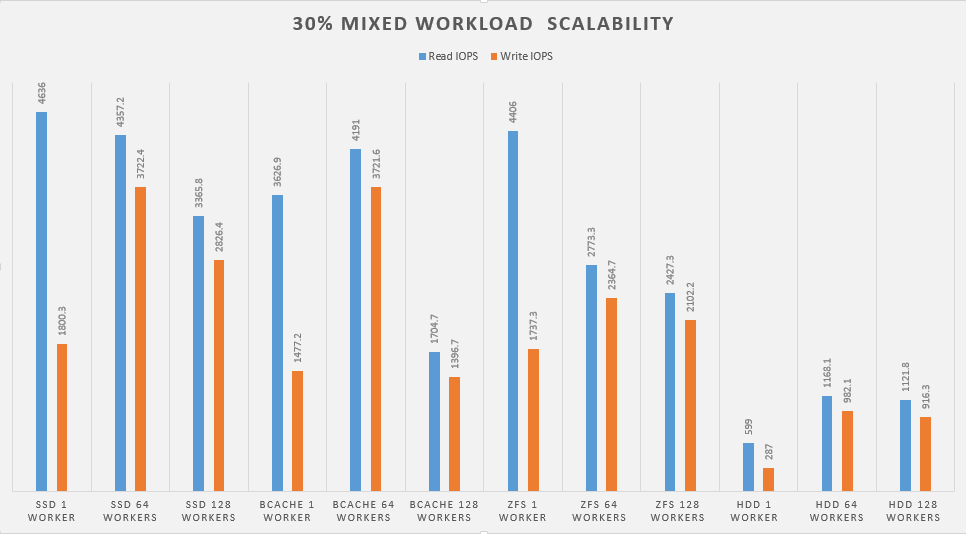
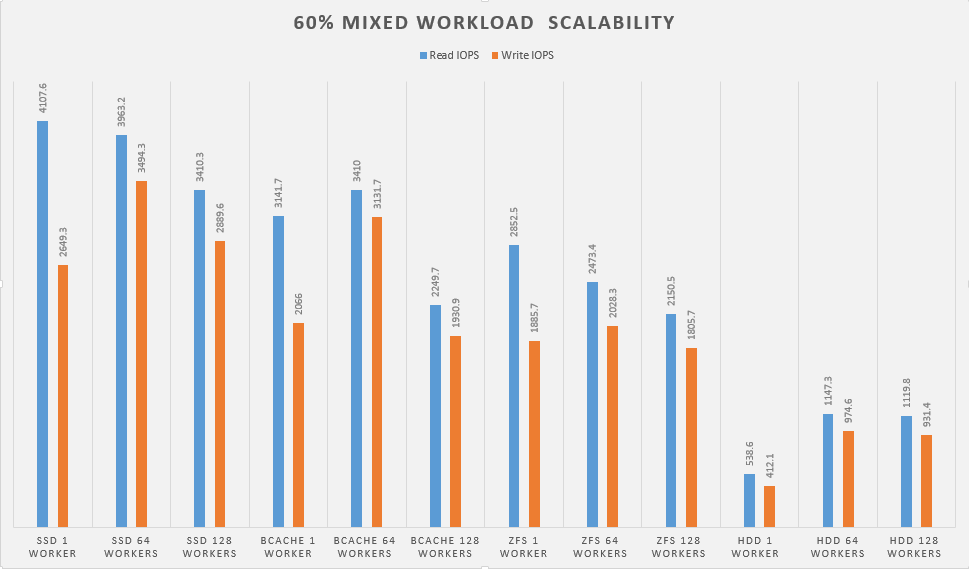
Final Thoughts
After I finished going through all the results, I think I’m going to call it and say that both bcache and ZFS seem like viable solutions. I pretty much ran bcache with the out of the box settings. There are a lot of adjustments that can be made that control how much data lives in the cache, cache algorithms and a few more that may squeeze out even more IOPS.
That said, I realize that while I had a single instance of Oracle seemingly do well, how scalable is this? For example, If I have 4 instances of Oracle, how scalable is cache in the pool? How do I determine the optimal quantity (GB and devices) of flash or SSD required for my hybrid storage array? That one question alone seems to require is own series of complex mathematical formulas and equations it seems. I came across an interesting white paper the expressed that same fact while researching for this post. I’ll dig it up and share it when I can.
Lastly, I realize that there is another caching solution for Linux that I did not review and that is dm-cache. Again, there is just so much data in this testing (I only shared like 20% of the raw data) and I just didn’t want to get overwhelmed so I completely ignored dm-cache. To be quite honest, I did a little happy dance when EnhanceIO didn’t work (lol). Less data for me to comb through. Come on, don’t look at me like that.
-Guru

Great Article, keep em coming #fusiondance
Nice article! I’m planning to look at using bcache (or EnhanceIO, or dm-cache) when I get some free time… the idea of using a bunch of cheap storage with a small amount of SSD storage up-front is very intriguing!
–Marc
I would use a “shared” (reachable from both nodes but not at same time) SSD device and use it with BTier instead of any of the options you tested.
Yeah I think btier may be a viable option. Perhaps I’ll test that this weekend.
why are testing zfs on top of md device instead of create zpool on top of raw disks?
Hmm I was trying to measure a different aspect of ZFS’s features. The pool was created on top of an existing RAID5 device + an SSD. I suppose I could have mirrored the SSD with ZFS then used the vdev to create the cache.
Very boring introduction, several times I thought of quitting.
Later things got interesting.
Well thanks for stopping by lol.
Very interresting. Can you share how you export data via SCST ? BIO or FIO ? When using ZFS, do you export files on ZFS pools, or do you export block devices (zvols) ?
Great Article very informative and well written
Great Article very informative and well written!
I would definitely re-run the ZFS tests. RAIDZ under certain workloads can be much more efficient that RAID5 due to variable width stripes. TYou should take a look at Matt Ahren’s blogpost http://blog.delphix.com/matt/2014/06/06/zfs-stripe-width/
Also, in defence of ZFS, I note your bcache config included a write cache, yet there is ZFS log device.
A really good article nonetheless.
I’m currently trying to work through the mechanics of using a pair of fusionio cards in separate machines to
HA bcache Ceph RBD block devices, then re-present as iSCSI targets. Given you’re HA-Guru.. any pointers
Sorry for the VERY late reply. The site was down for some time and I’m just now getting it back up.
That said, how is your project going? How large is your Ceph deployment?
HEYYY SQUIRREL I THING UR WEBSITE COULD USE SOME MORE SPARKELS AND FUN MINE CRAFT GAMES, THANKS!!!!!!!!
HARD CARRY, JUST RIGHT, STOP STOP IT, FLY,IF YOU DO
-got7lover
test
testing